
Студент кафедры вычислительной техники Университета ИТМО, участник Science Slam ITMO University 2.0
Коламбия Пикчерз не представляет: что могут рассказать данные IMDB
Студент кафедры вычислительной техники Юрий Волков рассказал в блоге на Хабрахабре, как анализировал датасет крупнейшего мирового хранилища информации о фильмах IMDB и к каким выводам пришел. Публикуем в блогах Университета ИТМО пост о том, как фильм «Зеленый слоник» вдохновил студента на серьезное исследование кинематографа.

Проблематика
Фильмы — это круто, фильмы вдохновляют нас, наполняют уверенностью, в общем, дают нам многое. И поэтому в этой статье я бы хотел рассказать вам об исследовании тенденций современного кинематографа с помощью инструментов анализа данных, который уже был презентован в финале Science Slam ITMO University 2.0. Полный выпуск доступен здесь.
Однажды на Кинопоиске я наткнулся на незнакомый фильм. Это оказался «Зеленый Слоник» — прославленная лента эпохи VHS. Те, кто слышали про него, могут понять мои чувства после прочтения странички об этом фильме на Википедии…

Но дурацких фильмов пруд пруди. Стоит ли им, вообще, уделять хоть какое-то внимание? А вот рейтинг этого фильма оказался аномально высоким. И это меня очень удивило. Как такой откровенный кинематографический «шлак» набрал рейтинг выше среднего?
И вот я, полный скептицизма и недоверия к Яндексу системе рейтингования, вооружился инструментами для анализа и визуализации данных на основе python стека (sklearn, pandas, matplotlib, numpy) и решил разобраться, почему у подобных фильмов могут появляться приличные рейтинги. Под катом вы найдете интересные и неочевидные выводы о современном (и не очень) кинематографе и информативные таблицы.
Данные в первую очередь
Итак, начинать надо с поиска данных, которые мы, собственно, и собираемся анализировать. Конечно, не очень хотелось собирать данные вручную — хотелось сразу сосредоточиться именно на их анализе. Поэтому я тут же начал искать нужный датасет в интернете. Нашёл его в том месте, куда стоило заглянуть в первую очередь, — на сайте kaggle.com. Это оказался датасет, содержащий более 5000 фильмов с известного сайта о кинематографе imdb. В признаковом описании каждого фильма содержалось немало категориальных и вещественных признаков, с которыми вы можете ознакомиться на страничке датасета.
Но так как мне изначально был интересен именно рейтинг Кинопоиска, поиск нужного датасета продолжился. АПИ Кинопоиска оказался закрыт, а писать парсер html страничек сервиса было лень не было времени из-за завала на учебе. Поэтому я решился и написал в службу поддержки Кинопоиска с просьбой предоставить датасет для исследования исключительно в академических целях. К большому удивлению мне даже ответили, но отказали. В итоге найти ничего другого не удалось. Датасет с Кинопоиска я обязательно соберу, но не ранее, чем после сессии. А сейчас для анализа пришлось взять данные IMDB.
Из чего состоит статья
Исследование найденного датасета разделилось на две объемные части:
- Обучение алгоритма предсказания (рейтинг фильма является целевой меткой);
- Поиск интересных и нетривиальных корреляций в данных.
В данной статье я хотел бы уделить больше внимания именно второй части исследования. Замечу лишь, что в первой части я пробовал обучать большое количество разных моделей. Точность предсказания, которой удалось добиться с помощью градиентного бустинга составляет 0.4 балла (mse ошибка) по шкале IMDB. Но процесс построения предсказательной модели заслуживает отдельной статьи, поэтому пока сосредоточусь на нетривиальных корреляциях в данных.
Начнем
Вторую часть своего исследования я начал с того, что взял алгоритм линейной регрессии с lasso регуляризацией, обученный в первой части, и построил диаграмму весовых коэффициентов признаков. Давайте взглянем на нее:
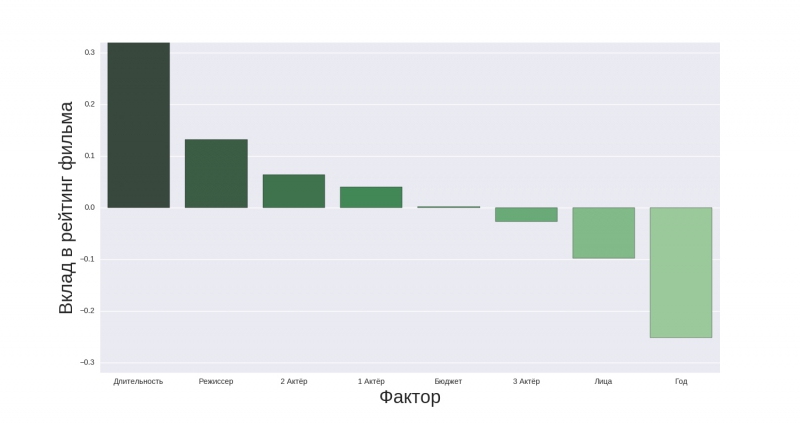
Столбцы «Режиссер», «[123] Актёр» соответствуют количеству лайков на Facebook у соответствующих личностей. «Формат» — это соотношение сторон картинки. «Лица» — это интересный вещественный признак, отражающий количество лиц на постере фильма. Значение остальных признаков очевидно. На данной диаграмме можно отметить несколько интересных моментов:
- Длительность фильма дает положительный вклад в рейтинг фильма (видимо, длинные фильмы лучше заходят зрителям);
- Год дает отрицательный вклад (чем новее фильм, тем больше вероятность, что рейтинг окажется низким);
- Большое количество лиц на постере также дает негативный вклад.
Последний пункт у меня, как у поклонника фильма «Отель Гранд-Будапешт», вызвал негодование, но с алгоритмом не поспоришь.
Жанр
Теперь давайте взглянем на, пожалуй, главный признак киноленты — «Жанр».
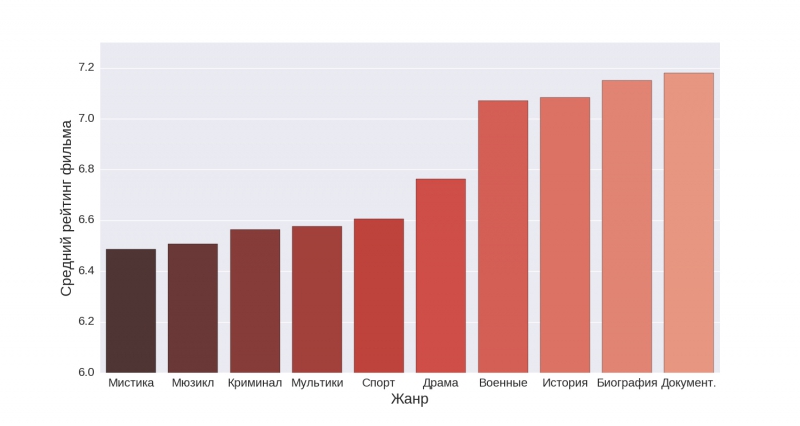
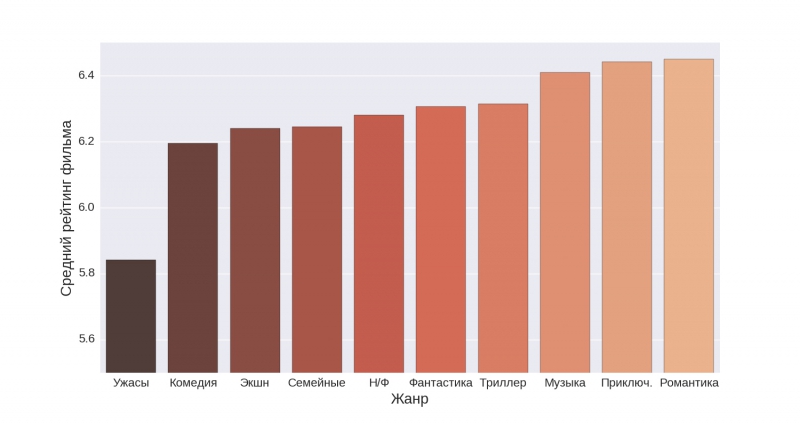
На первой диаграмме отображена первая десятка жанров, на второй — жанры с 11 по 20 место по среднему рейтингу.
Оказывается, наибольший рейтинг набирают документальные, биографические и исторические фильмы. В свою очередь, с большим отрывом наименьший рейтинг набирают хоррор-фильмы.
Страна производства
Достаточно интересный результат можно наблюдать на диаграмме, отражающей средний рейтинг фильма из различных стран. Давайте рассмотрим топ-6 стран по среднему рейтингу:
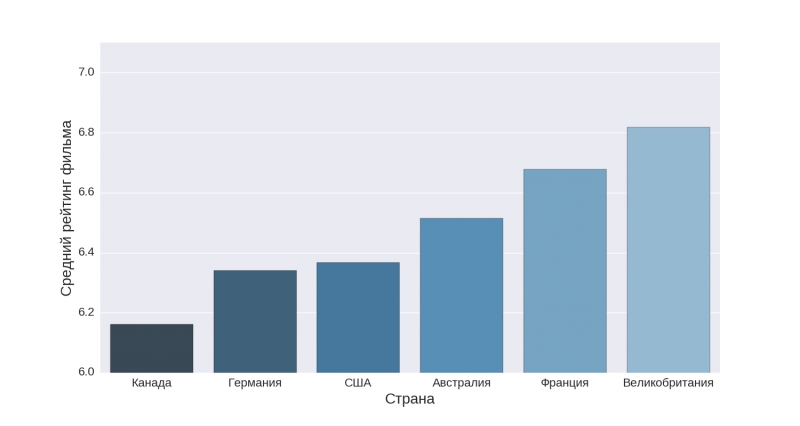
Как видим, наиболее рейтинговые фильмы (в среднем) снимают в Великобритании, после которой идет Франция, а вот Австралия на третьем месте стала весьма интересной неожиданностью. Лично мне трудно было сходу вспомнить высокорейтинговый фильм из Австралии. Погуглив, удалось выяснить, что к таковым относится недавно вышедший фильм «Безумный Макс: Дорога ярости». А вот то, что американцы заняли место вне тройки лидеров, весьма удивляет.
А теперь давайте взглянем на финансовую составляющую — на затраты каждой из стран на кинопроизводство:
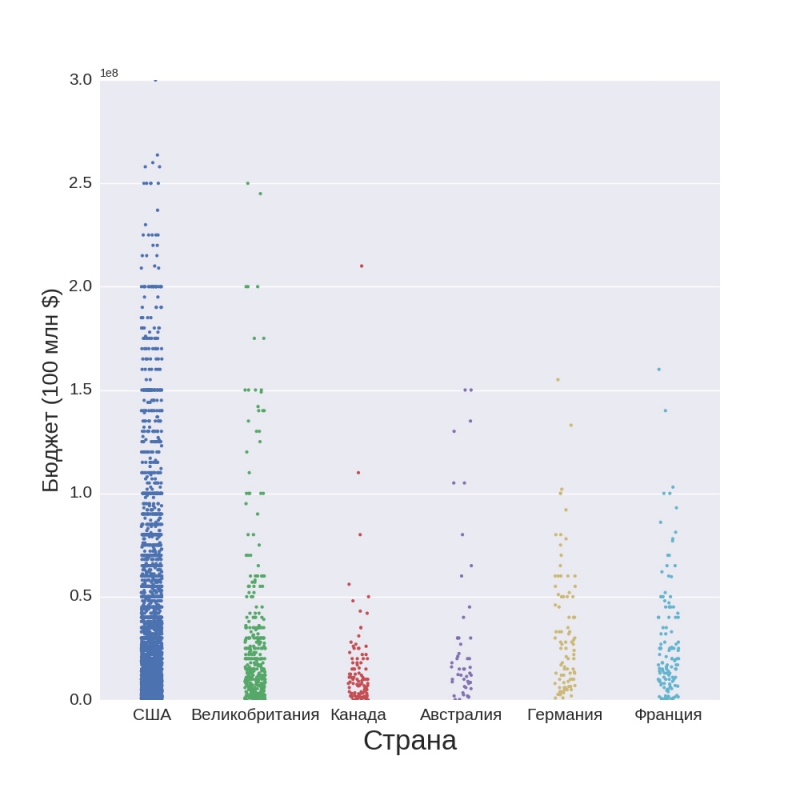
Тут все вполне ожидаемо: США лидирует с огромным отрывом, хотя это не стыкуется с предыдущей диаграммой. Получается, что американцы нерационально используют свои ресурсы, раз тратят больше, но по качеству проигрывают. Хотя никто не отрицает, что они могут «брать» не качеством, а количеством.
Время
Теперь давайте рассмотрим, как разные признаки фильмов зависят от времени. На данном графике отображается средний рейтинг фильмов в какой-то момент времени:
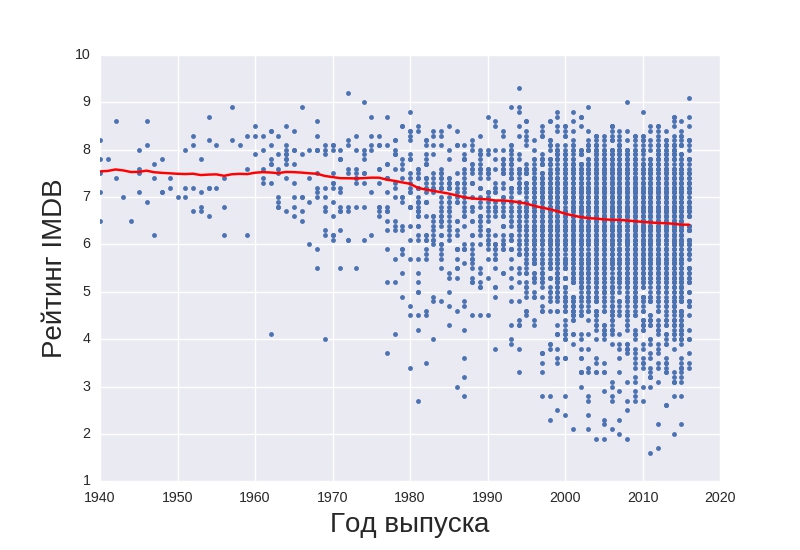
Можем увидеть, что средний рейтинг фильмов растет обратно пропорционально году выпуска фильма.
В свою очередь, этот факт не стыкуется с содержанием следующего графика:
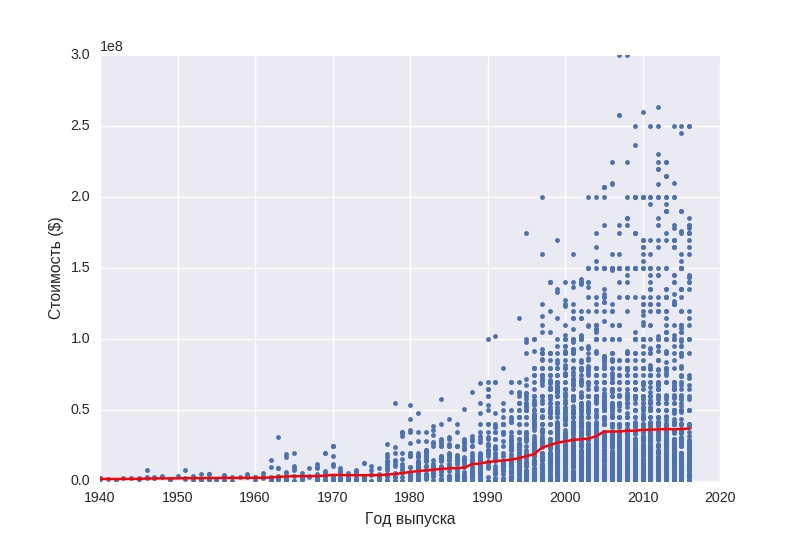
На данном графике отображена динамика изменения среднего бюджета фильма. Из последних двух графиков можно сделать вывод, что с годами мы тратим на фильмы больше, а получаем кино более низкого качества.
Также к весьма интересным выводам приводит график зависимости средней длительность фильма от времени:
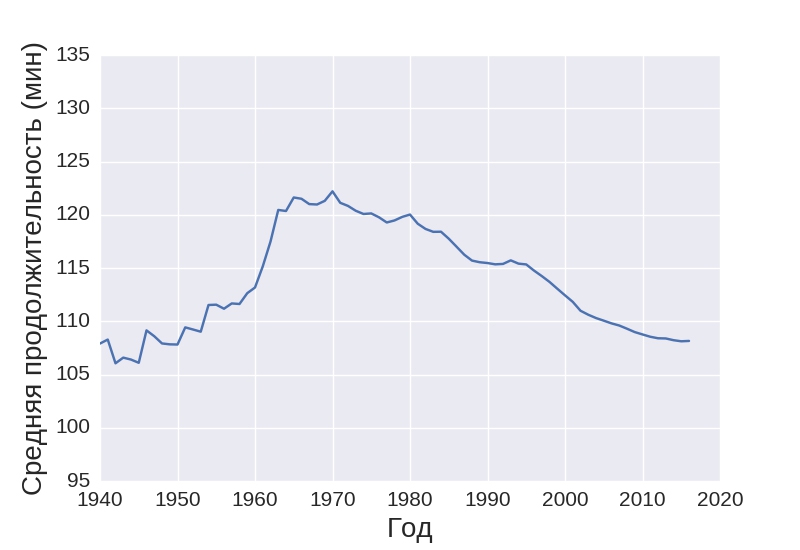
Можно видеть, что самые длительные фильмы снимали в 70-е годы. Найти этому точное объяснение непросто, могу лишь предположить, что в 70-е годы видео- и аудиоаппаратура получила серьезное развитие, в то же время у режиссеров и сценаристов было море идей, поэтому им было трудно остановить поток мыслей.
Выводы
Как видим, Data Mining-исследование дает весьма интересные результаты, и его методы могут быть использованы для анализа различных текущих процессов в одной из самых динамичных и быстроразвивающихся индустрий мира. Хорошим примером использования этих зависимостей на практике является сериал «Карточный домик». О том, как компания Netflix подбирала режиссеров и актеров с помощью методов анализа данных, вы можете прочитать здесь.